Data model
Scholarly opinion categorisation depending on logical status
Conjectures [parser], [Github] is a special graph that fully represents the semantics of point 3.4 of RDF 1.1: On Semantics of RDF Datasets: ``Named graphs are considered as `hypothetical graphs' which bear the same consequences as their RDF graphs, but they do not participate in the truth of the dataset; this allows a graph to contain contradictions without making the dataset contradictory;''. Like quoted triples in RDF-star, conjectures address expressed but not asserted claims (Expressing Without Asserting, EWA). Yet, conjectures apply to RDF graphs rather than individual triples.
A conjecture is an RDF 1.1 named graph specifically designed to express statements whose logical status is not explicitly stated. In this framework, all triples within the conjecture are expected to be consistent. Still, their absolute truth is neither stated nor available, and it does not affect the overall truth of the dataset. Conjectures adopt one of the possible semantics of Named graphs (item 3.4) while allowing other semantics to be expressed within the same dataset.
Thus, with conjectures, claims can be specified in different logical statuses than other reification methods that achieve EWA: undisputed and disputed.
- Undisputed claims are expressed as plain asserted (A) Named graphs. They are introduced by the keyword
GRAPH, such as GRAPH() → A. - Disputed claims are expressed as Conjectural graphs, which is a prototypical extension of the syntax of Trig, where the keyword
GRAPHis replaced withCONJin front of a graph whose contents is expressed but not asserted (¬ A), such as CONJ() → ¬ A. Conjectural graphs express those statements which are disputed or convey evolved knowledge.
Conjectures provide an effective solution to express without asserting the content of Named graphs. Additionally, conjectural graphs can be re-asserted using a supplementary graph called settled, which creates a dual state of claims as both conjectured and asserted simultaneously. This design ensures that the properties of conjectures hold regardless of the model-theoretic semantics chosen for Named graphs, a decision that RDF 1.1 does not explicitly settle.
- Settled claims record both the dispute, as well as its subsequent resolution. This approach is specifically and intentionally distinct from a mere re-assertion of disputed claims, as it neither acknowledges nor mentions the existence of the dispute. Settled Conjectures, a third type of named graph that is simultaneously conjectured and asserted and introduced by the keyword
SETTis introduced to handle settled disputes, such as SETT() → A ∧ ¬ A. The settle graphs allows to both represent the conjectural triples (inside the usual conjectural graph) as well as the same triples but completely asserted (inside the collapse graph). In addition, theconj:settlesrelation connects the conjecture and its settlement, simplifying the task of exploring the relationships between disputes and their settlements. The rationale behind Settled Conjectures is two-fold: on the one hand, to stress the difference between claims that have not been challenged and claims that emerged as winning among competing and incompatible hypotheses and on the other to represent the dual nature of settled claims as both conjectures and assertions.
Scholalry opinion representation
Conjectures has been used as the reification method to represent the claims' logical status and reach EWA when needed. Information that is not disputed is structured as a distinct named graph named factual_data as suggested in the Digital Hermeneutics data model [daquino2020], so their contents are asserted. Disputed claims are represented through conjectural graphs, therefore not asserting their contents. Finally, accepted scholarly claims are represented as settled conjectures, re-asserting their contents through a settled.
Despite its logical status, each graph is associated with the set of available contextual information (e.g., the bibliography mentioned, the evidence collected).
Regarding the scholarly opinions reported in the cited bibliography of each document in the catalogue, their logical status will be further decided depending on their contents with respect to Haider's settled perspective as he believes or disbelieves such opinions. All reused prefixes are provided in listing [Listing 1].
@prefix dct: <http://purl.org/dc/terms/> .
@prefix geo: <http://www.opengis.net/ont/geosparql#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix riopac: <http://opac.regesta-imperii.de/id/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix prov: <http://www.w3.org/ns/prov#> .
@prefix hico: <https://w3id.org/hico#> .
@prefix sebi: <https://w3id.org/sebi/> .
@prefix time: <https://www.w3.org/TR/owl-time/> .
@prefix wd: <http://www.wikidata.org/entity/> .
@prefix cito: <http://purl.org/spar/cito/> .
@prefix fabio: <http://purl.org/spar/fabio/> .
@prefix ov: <http://open.vocab.org/terms/> .
@prefix rico: <https://www.ica.org/standards/RiC/ontology#> .
@prefix conj: <https://w3id.org/conjectures/> .
@prefix : <https://w3id.org/broast/urk/> .
@prefix doc: <https://w3id.org/broast/urk/documents/> .
@prefix people: <https://w3id.org/broast/urk/scholars/> .
@prefix pub: <https://w3id.org/broast/urk/publications/> .
Each claimed content attempts to classify a document's authenticity by expressing information about the document itself, which usually may be debated: authenticity classification (e.g. the document is authentic, is suspicious or is a forgery), date and place of creation, suspected author. All these elements should be expressed in the conjectural graph (despite being settled or currently disputed), but none is required. In simpler terms, a scholarly opinion proposes a date (e.g., 950-1000) and documents juridical categorisation (e.g., forgery) but neglects its authorship (e.g., a suspected author is unknown or simply not considered).
SEBI ontology (Scholarly Evidence Based Interpretation ontology) is a simple pattern representing the evidence scholars collect to support their interpretations. In particular, the ontology is provided with a set of Named Individuals and Classes which characterise the use of the ontology to represent the evidence which supports scholarly interpretations about the classification of a document's authenticity (in particular by defining such document an Authentic document, a Forgery or a Suspected Forgery). The data model, therefore, integrates SEBI ontology and other existing ontologies such as Dublin Core Terms to describe the document metadata and bibliographical entries descriptions, Time ontology to handle fuzzy datings, as shown in Figure 1.
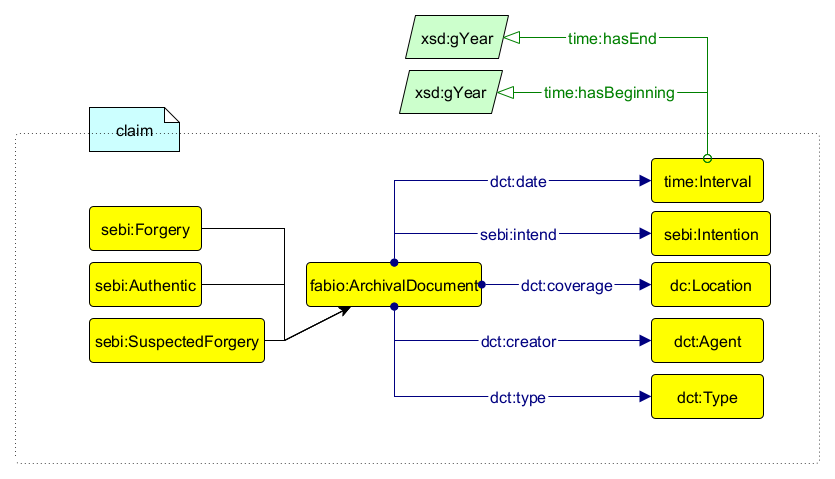
Documents categorisations are formalised as instances of one of the classes sebi:Forgery, sebi:Authentic, and sebi:SuspectedForgery, and they are all disjoint mimicking the need to choose a single point of view in each claimed content (if no conclusion can be reached, other metadata as date, place and author should be registered). Each document is an instance of the class fabio:ArchivalDocument. The creator of the document (expressed through dct:creator dct:Agent), the date of creation ( dct:date time:Interval), location of creation ( dct:coverage dct:Location). The dct:date property is connected to a time:Interval class, which includes time:hasBeginning and time:hasEnd properties to specify the creation period and handle fuzzy time-spans. Even if not recorded in the catalogue, the intention behind the document creation is formalised via introducing a new class and predicate ( sebi:intended sebi:Intention). Additionally, dates can be annotated with rico:dateQualifier and other entities with rico:confidence to record uncertainty related markers (e.g., circa, possibly).
Regardless of their logical status or origin, all opinions about document forgery detection can be represented using at least one of the classes and properties described and illustrated in Figure 1.
For instance, Figure 2 illustrates four of the available opinions involved in the authenticity inquiry of the 12th document of the collection ( doc:12) modelled with the data model just introduced.

Representation of opinions contextual information
Contextual information about the opinion concern those aspects which have been highlighted at the beginning of this section, such as the evidence collected by the scholar to reach a certain conclusion (using HiCo ) and SEBI, as well as the author of the opinion and relevant bibliographic entries using PROV-o and Dublin Core.
As shown in Figure 1, each graph storing a scholarly opinion is categorised as a rdf:type hico:InterpretationAct. The bibliographic source (instance of fabio:WorkCollection or Expression) from which the opinion is extracted is represented via the property prov:wasQuotedFrom. Similarly, cited bibliographic resources are modelled via the property prov:wasDerivedFrom and the opinion responsible entity is recorded via the property prov:wasAttributedTo prov:Agent. Each bibliographical resource is represented with a set of object and data properties from Dublin Core vocabulary representing main features of the work, such as the title dct:title, a brief description dct:description, publishing date ( dct:date), the language dct:language, main subjects dct:subject and involved agents ( dct:creator, dct:publisher, dct:contributor). When dealing with disputed opinions, the source of the opinion is ideally stated in the document itself, for this reason, the source of such opinions is represented as prov:wasQuotedFrom fabio:ArchivalDocument.
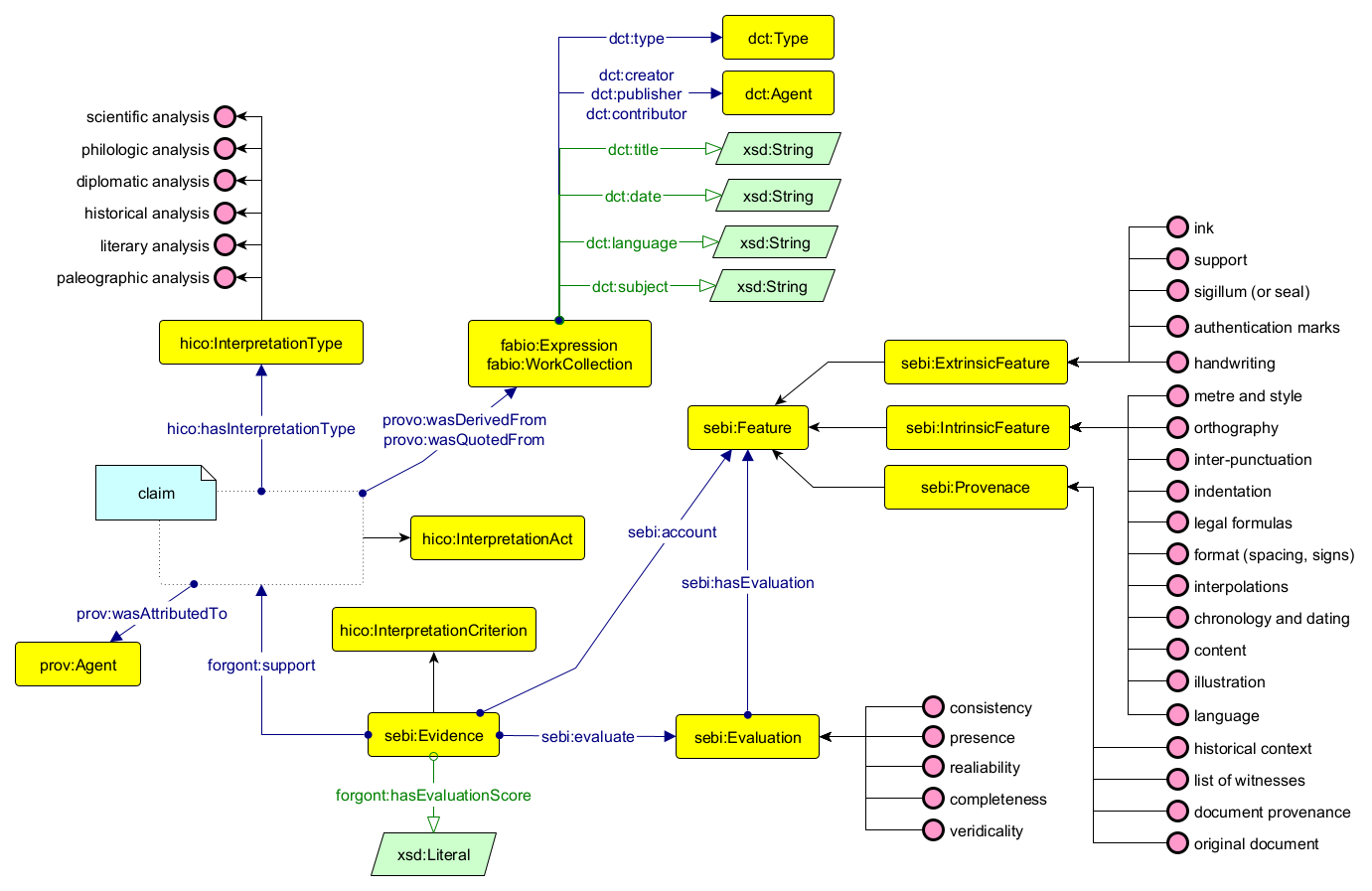
The evidence supporting the opinion is recorded as ( sebi:support sebi:Evidence). Document features and their evaluation are considered as critical components of the ontology. Document features ( sebi:Feature) are either extrinsic features ( sebi:ExtrinsicFeature), intrinsic ones ( sebi:IntrinsicFeature), or provenance information ( sebi:Provenance), capturing aspects such as ink, support, handwriting, and orthography. Each feature is evaluated on a set of established criteria ( sebi:Evidence) such as consistency, presence, completeness, veridicality, and reliability. A score is associated with each evidence as xsd:Literal using the property forgont:hasEvaluationScore. The evaluation score indicates a measure on each collected evidence, allowing the integration of negatives (e.g. the absence of the signature in a document is represented as an evidence based on the feature "authentication marks" with evaluation "presence", with score false or 0).
Therefore, the contextual metadata concerning the four opinions represented in Figure 2 are shown in Figure 3. In particular, Haider's opinion (in yellow) is enriched with its source ( prov:wasQuotedFrom :ref-Urkundenverzeichnis), its author ( prov:wasAttributedTo :person-SiegfriedHaider), the bibliographic resources mentioned ( prov:wasDerivedFrom pub:1284, pub:1292) and the evidence collected to support its opinion ( :evidence1 sebi:support). Haider's collected evidence is based on the account of the stylistic features of the document ( sebi:account sebi:style, which is an instance of the class sebi:IntrinsicFeatures), producing an evaluation ( sebi:evaluate sebi:coherency, which is an instance of the class sebi:Evaluation). The evaluation score of this evidence is "False" ( sebi:hasEvaluationScore "False"xsd:boolean), therefore stating the evidence as "incoherent style".
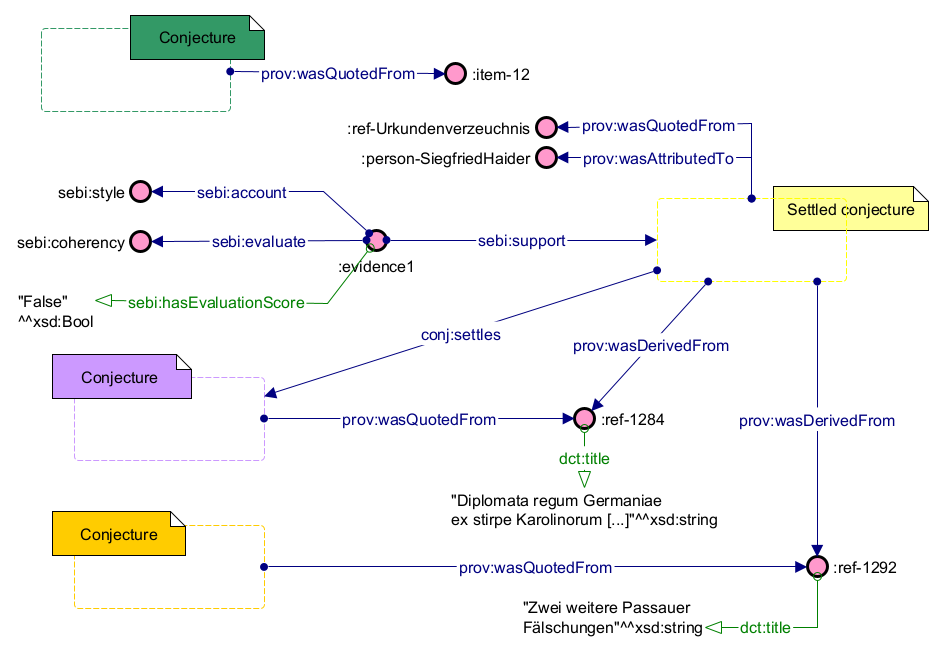
Haider's opinion correlates with Mulbacher's and Schieffer's (respectively, marked in purple and orange) by the bibliographic resources pub:1284, pub:1292. These resources are the source from which the two opinions are derived ( prov:wasQuotedFrom), while the source of the disputed opinion, marked in green, is reported to be the document itself ( prov:wasQuotedFrom doc:12). Each bibliographic resource is accompanied by a set of descriptive metadata previously described. These are exemplified in Figure 4 by the resources' titles ( dct:title), while other metadata are omitted for clarity.